挺复杂的一题,用了多个dp数组来保存过程量
Given a sequence of words, and a limit on the number of characters that can be put in one line (line width). Put line breaks in the given sequence such that the lines are printed neatly.Assume that the length of each word is smaller
than the line width.
The word processors like MS Word do task of placing line breaks. The idea is to have balanced lines. In other words, not have few lines with lots of extra spaces and some lines with small amount of extra spaces.
The extra spaces includes spaces put at the end of every line except the last one.
The problem is to minimize the following total cost.
Cost of a line = (Number of extra spaces in the line)^3
Total Cost = Sum of costs for all lines
For example, consider the following string and line width M = 15
"Geeks for Geeks presents word wrap problem"
Following is the optimized arrangement of words in 3 lines
Geeks for Geeks
presents word
wrap problem
The total extra spaces in line 1, line 2 and line 3 are 0, 2 and 3 respectively.
So optimal value of total cost is 0 + 2*2 + 3*3 = 13
Please note that the total cost function is not sum of extra spaces, but sum of cubes (or square is also used) of extra spaces. The idea behind this cost function is to balance the spaces among lines. For example, consider the following two arrangement of same
set of words:
1)There are 3 lines. One line has 3 extra spaces and all other lines have 0 extra spaces. Total extra spaces = 3 + 0 + 0 = 3. Total cost = 3*3*3 + 0*0*0 + 0*0*0 = 27.
2)There are 3 lines. Each of the 3 lines has one extra space. Total extra spaces = 1 + 1 + 1 = 3. Total cost = 1*1*1 + 1*1*1 + 1*1*1 = 3.
Total extra spaces are 3 in both scenarios, but second arrangement should be preferred because extra spaces are balanced in all three lines. The cost function with cubic sum serves the purpose because the value of total cost in second scenario is less.
Method 1 (Greedy Solution)
The greedy solution is to place as many words as possible in the first line. Then do the same thing for the second line and so on until all words are placed. This solution gives optimal solution for many cases, but doesn’t give optimal solution in all cases.
For example, consider the following string “aaa bb cc ddddd” and line width as 6. Greedy method will produce following output.
aaa bb
cc
ddddd
Extra spaces in the above 3 lines are 0, 4 and 1 respectively. So total cost is 0 + 64 + 1 = 65.
But the above solution is not the best solution. Following arrangement has more balanced spaces. Therefore less value of total cost function.
aaa
bb cc
ddddd
Extra spaces in the above 3 lines are 3, 1 and 1 respectively. So total cost is 27 + 1 + 1 = 29.
Despite being sub-optimal in some cases, the greedy approach is used by many word processors like MS Word and OpenOffice.org Writer.
Method 2 (Dynamic Programming)
The following Dynamic approach strictly follows the algorithm given insolution of Cormen book.First we compute
costs of all possible lines in a 2D table lc[][]. The value lc[i][j] indicates the cost to put words from i to j in a single line where i and j are indexes of words in the input sequences. If a sequence of words from i to j cannot fit in a single line, then
lc[i][j] is considered infinite (to avoid it from being a part of the solution). Once we have the lc[][] table constructed, we can calculate total cost using following recursive formula. In the following formula, C[j] is the optimized total cost for arranging
words from 1 to j.

The above recursion hasoverlapping subproblem property. For example, the solution of subproblem c(2) is used by c(3), C(4) and so on.
So Dynamic Programming is used to store the results of subproblems. The array c[] can be computed from left to right, since each value depends only on earlier values.
To print the output, we keep track of what words go on what lines, we can keep a parallel p array that points to where each c value came from. The last line starts at word p[n] and goes through word n. The previous line starts at word p[p[n]] and goes through
word p[n] – 1, etc. The function printSolution() uses p[] to print the solution.
In the below program, input is an array l[] that represents lengths of words in a sequence. The value l[i] indicates length of the ith word (i starts from 1) in theinput sequence.
http://www.geeksforgeeks.org/dynamic-programming-set-18-word-wrap/
另外可以参考wiki的这篇:https://zh.wikipedia.org/wiki/%E8%87%AA%E5%8A%A8%E6%8D%A2%E8%A1%8C
在TeX中使用的,则是另一个算法,旨在将行尾空格数的平方最小化,以产生一个更加美观的结果。以上的算法不能完成这一目标,例如:
aaa bb cc ddddd
如果惩罚函数定义为行尾剩余空格数的平方,则贪婪算法会得到一个次优解(为了简化起见,不妨假设采用定宽字体):
------ 一行的宽度为6
aaa bb 剩余的空格数:0,平方=0
cc 剩余的空格数:4,平方=16
ddddd 剩余的空格数:1,平方=1
总计代价17,而最佳的解决方案是这样的:
------ 一行的宽度为6
aaa 剩余空格数:3 平方=9
bb cc 剩余空格数:1 平方=1
ddddd 剩余空格数:1 平方=1
请注意,第一行在bb前断开了,相对于在bb后断开的解法,可以得到更好的右边界和更低的代价11。
为了解决这个问题,我们需要定义一个惩罚函数 ,用于计算包含单词
,用于计算包含单词![\text{Word}[i]](https://upload.wikimedia.org/math/9/a/3/9a3db94ed54fc03d4c28f5c1bb267070.png) 到单词
到单词![\text{Word}[j]](https://upload.wikimedia.org/math/a/6/b/a6bb3a0c74947f53c59d43d8d4f2320f.png) 的一行的代价:
的一行的代价:
![c(i, j) = \left(\text{LineWidth}-(j-i)\cdot\text{OneSpaceWidth}-\sum_{k=i}^j \text{WidthOf}(\text{Word}[k])\right)^P.](https://upload.wikimedia.org/math/7/2/d/72debb2b089c75e265331fa05e41306f.png)
其中 通常为
通常为 或
或 。另外,有一些特殊的情况值得考虑:如果结果为负(即单词串不能全部放在一行里),惩罚函数需要反映跟踪或压缩文本以适应一行的代价;如果这是不可能的,则返回
。另外,有一些特殊的情况值得考虑:如果结果为负(即单词串不能全部放在一行里),惩罚函数需要反映跟踪或压缩文本以适应一行的代价;如果这是不可能的,则返回
最优解的代价可以用以下的递归式定义:

这可以利用动态规划来高效地实现,时间和空间复杂度均为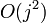
package DP;
import java.util.Arrays;
public class WordWrap {
public static void main(String[] args) {
int[] l = {3, 2, 2, 5};
int n = l.length;
int M = 6;
solveWordWrap(l, n, M);
}
// l[] represents lengths of different words in input sequence. For example,
// l[] = {3, 2, 2, 5} is for a sentence like "aaa bb cc ddddd". n is size of
// l[] and M is line width (maximum no. of characters that can fit in a line)
// Time Complexity: O(n^2) Auxiliary Space: O(n^2)
public static void solveWordWrap(int[] l, int n, int M){
// For simplicity, 1 extra space is used in all below arrays
// extras[i][j] will have number of extra spaces if words from i
// to j are put in a single line
// extras[i][j]记录把单词序号i到j放在一行后剩余的空格数目
int[][] extras = new int[n+1][n+1];
// lc[i][j] will have cost of a line which has words from i to j
// lc[i][j]记录把单词序号i到j放在一行后导致的花费cost
int[][] lc = new int[n+1][n+1];
// c[i] will have total cost of optimal arrangement of words from 1 to i
// c[i]记录了把单词序号从1到i放在多行后导致的总的最小花费
int[] c = new int[n+1];
// p[] is used to print the solution.
// p[n]记录了单词编号p[n]到n被放在了同一行
int[] p = new int[n+1];
// calculate extra spaces in a single line. The value extra[i][j]
// indicates extra spaces if words from word number i to j are
// placed in a single line
for(int i=1; i<=n; i++){
extras[i][i] = M-l[i-1]; // 如果只有一个单词,则剩余空格数为M扣除这个单词的长度
for(int j=i+1; j<=n; j++){ // 否则剩余空格数为上一次剩余空格数扣除接下来用的单词长度
extras[i][j] = extras[i][j-1]-l[j-1]-1; // 因为单词之间要有空格隔开,所以多扣除一个1
}
}
// print(extras);
// Calculate line cost corresponding to the above calculated extra
// spaces. The value lc[i][j] indicates cost of putting words from
// word number i to j in a single line
for(int i=1; i<=n; i++){ // 起始单词序号
for(int j=i; j<=n; j++){ // j:结尾单词序号,j肯定大于i,因为j指向的单词在i之后
if(extras[i][j] < 0){ // 空格数为负说明,放不下所以设为最大值
lc[i][j] = Integer.MAX_VALUE;
}else if(j==n && extras[i][j]>=0){ // 最后一个单词,后面有空格也无所谓
lc[i][j] = 0;
}else{ // 其余情况cost为空格数的平方
lc[i][j] = extras[i][j]*extras[i][j];
}
}
}
// Calculate minimum cost and find minimum cost arrangement.
// The value c[j] indicates optimized cost to arrange words
// from word number 1 to j.
c[0] = 0;
for(int j=1; j<=n; j++){ // 依次计算单词数目为j时的最小cost
c[j] = Integer.MAX_VALUE;
for(int i=1; i<=j; i++){ // i: 把i...j放在一行,然后计算剩下1...i的放法
if(c[i-1]!=Integer.MAX_VALUE && lc[i][j]!=Integer.MAX_VALUE // 防止溢出
&& c[i-1]+lc[i][j]<c[j]){
c[j] = c[i-1] + lc[i][j]; // 记录更小的花费
p[j] = i; // 单词数目为j时,最优放法是1...i放在前几行,把i...j放在最后一行
}
}
}
printSolution(p, n);
// System.out.println(Arrays.toString(p));
}
// 递归返回出最后一行的行号k, 每一行的单词序号总是由p[n]开始到n结尾
public static int printSolution(int[] p, int n){
int k;
if(p[n] == 1){
k = 1;
}else{
k = printSolution(p, p[n]-1)+1; // 上一行行号加一,p[n]为开始的单词序号,所以p[n]-1就是上一行的结尾单词序号
}
System.out.format("Line number %d: From word no. %d to %d \n", k, p[n], n);
return k;
}
public static void print(int[][] A){
for(int i=0; i<A.length; i++){
for(int j=0; j<A[0].length; j++){
System.out.print(A[i][j] + "\t");
}
System.out.println();
}
}
}
分享到:




相关推荐
自动换行布局,水平排列子项,并自动换行,支持不等长不等宽子项,且可以设置垂直间距与水平间距及子项对齐模式。要求minSdkVersion 4引用dependencies { ⋯ compile 'am.widget:wraplayout:1.1.0' ⋯ }...
各种数据结构、算法及实用的C#源代码.C#,动态规划(DP)金矿问题(Gold Mine Problem)的算法与源代码.给定一个N*M尺寸的金矿,每个点都有一个非负数表示当前点所含的黄金数目,最开始矿工位于第一列,但是可以位于...
Simple DP Problem:数塔问题
DP日常维护常见问题
C#,动态规划的集合划分问题(DP Partition problem)算法与源代码 1 动态规划问题中的划分问题 动态规划问题中的划分问题是确定一个给定的集是否可以划分为两个子集,使得两个子集中的元素之和相同。 动态规划...
C#,动态规划(DP)N皇后问题(N Queen Problem)的回溯(Backtracking)算法与源代码 在N*N的方格棋盘放置了N个皇后,使得它们不相互攻击(即任意2个皇后不允许处在同一排,同一列,也不允许处在与棋盘边框成45角的...
文首先舟绍了现场总线PROFIBUS的概念、组成及其特点.然后详细介绍7现场总线PROFIBUSDP在擎成铜有限责任公司_qb340连轧管机组娇
很多影视站长都在搜索关于本地播放器实现自动播放下一集的解决方案,(*-*) 我也一样!然而经过一段时间的努力在一个很给力的博客里找到了。挖出来发给各位,直接替换就OK了。记得先备份之前的,以防不兼容问题导致...
Android 蓝牙 A2dp 听歌卡音?audio数据到a2dp通道流程解析----A2dp流控原理(Acl Flow Control),一文搞懂蓝牙卡音问题处理
区间DP概率DP树形DP插头DP,每种DP一道典型例题,有助于初学者
得宝 迪普乐DP-F850 DP-F650 DP-F620 DP-F550 DP-F520 制版印刷一体机 维修手册
蓝牙A2DP最新协议版本,A2DP_v1.3.2.pdf;蓝牙A2DP最新协议版本,A2DP_v1.3.2.pdf;蓝牙A2DP最新协议版本,A2DP_v1.3.2.pdf;蓝牙A2DP最新协议版本,A2DP_v1.3.2.pdf;蓝牙A2DP最新协议版本,A2DP_v1.3.2.pdf;蓝牙A...
DP83848中文数据手册 DP83848中文文档 全篇翻译无排版 DP83848C / I / VYB / YB PHYTER™QFP单端口10/100 Mb / s以太网物理层收发器 从–40°C到105°C的多个温度范围•IEEE 802.3 ENDEC,10BASE-T收发器和 • 低...
动态规划的应用极其广泛,包括工程技术、经济、工业生产、军事以及自动化控制等领域,并在背包问题、生产经营问题、资金管理问题、资源分配问题、最短路径问题和复杂系统可靠性问题等中取得了显著的效果。扔鸡蛋问题...
需要ppt讲解 动态规划-dp(电路布线问题)
动态规划(DP)——背包问题算法详解[背包九讲]
3.1 DP软件的自动启动配置 5 3.2 DP软件的手工启动方法 5 3.3 DP软件的后台进程 5 4 DP软件图形界面中各部分的说明 5 4.1 Clients模块 6 4.2 Users模块 9 4.3 Devices & Media模块 12 4.4 Backup模块 16 4.5 Monitor...
一种基于PROFIBUS-DP总线控制的自动定量灌装系统pdf,一种基于PROFIBUS-DP总线控制的自动定量灌装系统
DP_问题 添加者 - Manish Kumar 编号 问题 关联 相关概念 日期 代码 1 买苹果 无界背包 6/4/20 2 动物 0-1 背包 6/4/20 3 凯撒军团 DP 6/4/20 3a DP writeup + Caeser Legion 解决方案 DP 8/4/20 4 数字DP博客 数字...
背包问题(Knapsack Problem)是一个经典的组合优化问题,通常分为两种类型:0/1背包问题和分数背包问题。 1. **0/1背包问题**: - 给定一组物品,每个物品都有自己的重量和价值,要求在给定的背包容量下,选择...